Challenge website: https://adodas.hai-lab.cn/
1. Abstract
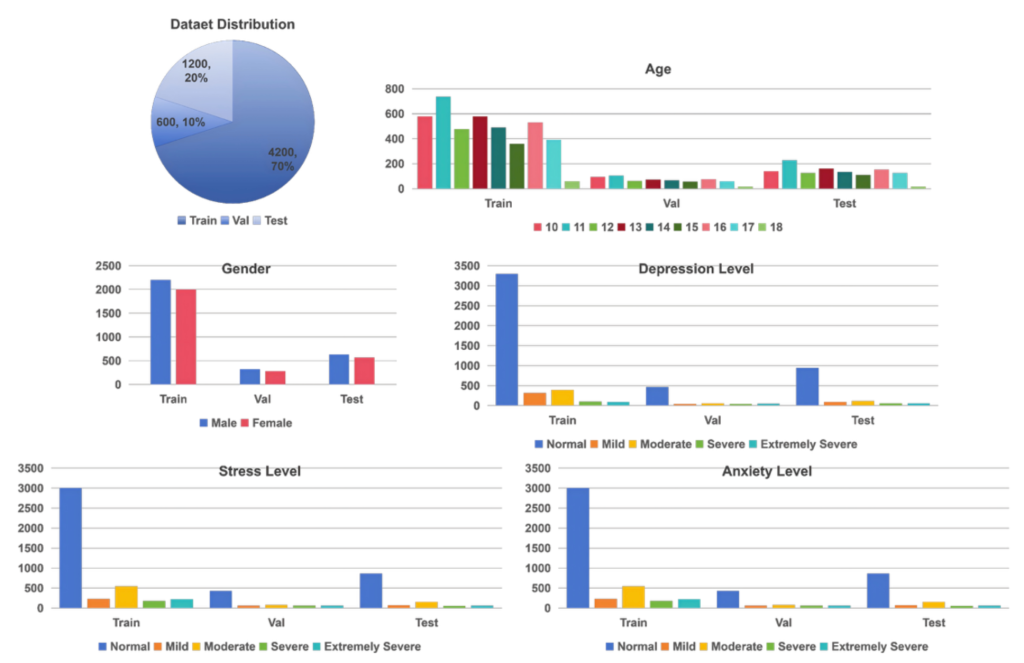
As mental health issues among adolescents become increasingly prominent, early screening and timely intervention are crucial. How to conduct scalable, reproducible, and comparable intelligent assessment research while ensuring privacy and ethical safety has become an important topic in multimodal intelligence and digital health. To this end, we proudly introduce the AdoDAS multimodal challenge. This is a large-scale, privacy-preserving multimodal dataset consisting of 6,000 child and adolescent participants and a total of 24,000 audio-video clips.
The data for this challenge are collected under a strictly controlled school environment protocol, combining standardized text reading and open-ended interview prompts. Ground-truth labels are derived from the DASS-21 scale, providing scores for three subscales—Depression, Anxiety, and Stress—as well as item-level feedback for 21 questions. Unlike previous competitions that focus on social media or adult interviews, AdoDAS specifically targets minors and adopts strict privacy protection mechanisms. Raw audio and video are not released; instead, only reproducible precomputed features and cross-modal temporal metadata are provided. We offer two benchmark tracks and baseline models to promote safe and reliable multimodal mental health research.
2. Introduction and Background
Adolescence is a critical period for identifying mental health issues and providing early intervention. Depression, anxiety, and stress not only have high prevalence rates but also frequently co-occur. In real-world scenarios, psychological screening still heavily relies on questionnaires and limited professional resources, making large-scale, continuous, and low-burden assessment challenging.
In recent years, advances in multimodal affective computing have shown that speech characteristics, facial behaviors, motion patterns, and temporal dynamics during human interaction can provide valuable complementary signals for mental state assessment. However, most existing public resources focus on adult interviews, social media text, or “in-the-wild” data. Truly minor-oriented multimodal benchmarks that also balance privacy protection and standardized evaluation remain extremely scarce.
Among these, there are two core challenges:
First, privacy and ethical constraints. For children and adolescent data, even after conventional anonymization, raw audio and video may still pose risks of identity re-identification, which greatly limits direct data release.
Second, inconsistent evaluation standards. Differences in datasets, task definitions, splitting strategies, and metric settings can easily lead to incomparable results and even subject leakage, affecting the reliability of model evaluation.
AdoDAS is proposed in this context: to build a reproducible, comparable, and extensible multimodal challenge platform under the premise of ensuring the safety of minors’ data, providing a new research benchmark for adolescent mental health assessment.
3. Key Highlights
- Focus on adolescent mental health assessment
AdoDAS is no longer limited to adult interviews or social media text, but instead focuses on children and adolescents, targeting three key dimensions: depression, anxiety, and stress, making it more aligned with real-world mental health screening needs.
- Large-scale, multimodal, standardized collection
The dataset covers 6,000 participants and 24,000 audio-video samples. Each participant includes four recording segments: one standardized reading task (A01) and three open-ended Q&A tasks (B01–B03), balancing controlled and natural expression scenarios.
- Privacy-first release mechanism
AdoDAS does not release raw audio, raw video, or identifiable facial frame images. Instead, it provides precomputed features and temporal metadata, reducing privacy risks while offering researchers directly usable modeling inputs.
- Support for coarse-grained screening and fine-grained modeling
Labels are derived from DASS-21, providing both subscale scores for depression, anxiety, and stress, as well as responses to all 21 items. This enables researchers to perform binary classification screening as well as explore more fine-grained and interpretable symptom modeling tasks.
4. Challenge Tracks
This challenge includes two tracks:
Track 1: Multi-task binary screening (Track A1)
This track focuses on screening tasks for three dimensions: Depression / Anxiety / Stress (D/A/S). For each sample, participants are required to predict whether it belongs to “Normal” or “Mild-or-above” in each dimension, i.e., completing three binary classification tasks.
For evaluation, the primary metric of Track 1 is the average F1 score across the three tasks, with average AUROC as a secondary metric to measure overall discriminative performance in screening tasks.
Track 2: DASS-21 item response prediction and subscale reconstruction (Track A2)
This track further increases task granularity. Participants are required to predict the scores of all 21 DASS-21 items for each sample, with each item ranging from 0–3. Based on these predictions, the official evaluation will reconstruct the depression, anxiety, and stress subscale scores according to standard DASS-21 rules.
The primary metric for Track 2 is the average QWK across the 21 items, with average MAE as a secondary metric to evaluate overall consistency and deviation between predictions and ground truth at the item level.
5. Baseline System
We provide participants with a fully feature-based, privacy-preserving temporal baseline model. The model adopts a modular design, with core components including:
- Group-wise adapters: Mitigate scale mismatch between low-dimensional behavioral features and high-dimensional SSL embeddings.
- Temporal encoders: Use residual dilated temporal convolution blocks to capture local dynamics and long-range trends on a 25Hz timeline.
- Mask-aware pooling: Combine temporal metadata and visual quality signals to reduce the impact of missing or low-quality frames.
- Fusion and multi-task heads: Designed for Tracks A1 and A2, including binary classification heads and ordered regression/classification heads for 21 items.
6. Important Timeline
| Data, website, baseline and code available | 21 Mar, 2026 |
| Results submission start | 09 May, 2026 |
| Results submission deadline | 20 May, 2026 |
| Deadline for paper submission | 28 May, 2026 |
| Paper acceptance notification | 16 Jul, 2026 |
| Deadline for camera-ready papers | 06 Aug, 2026 |